stage4day3section3-4
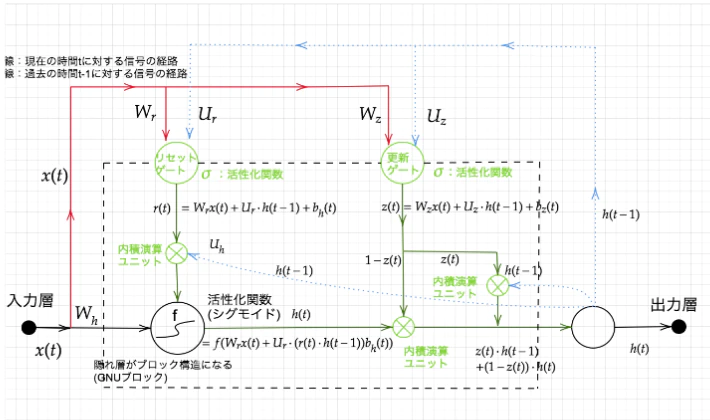
Section3:GRU
・LSTMはパラメータ数が多く、計算負荷が大きい
・GRUは - パラメータを大幅に削減し、精度は同等以上が望めるようになった構造 - 計算負荷が低い
確認テスト

答え
LSTMはパラメータ数が多く、計算コストが大きい
CECは覚えることのみで学習はしないため、CECの周りにその他の機能を配置する必要がある
演習チャレンジ
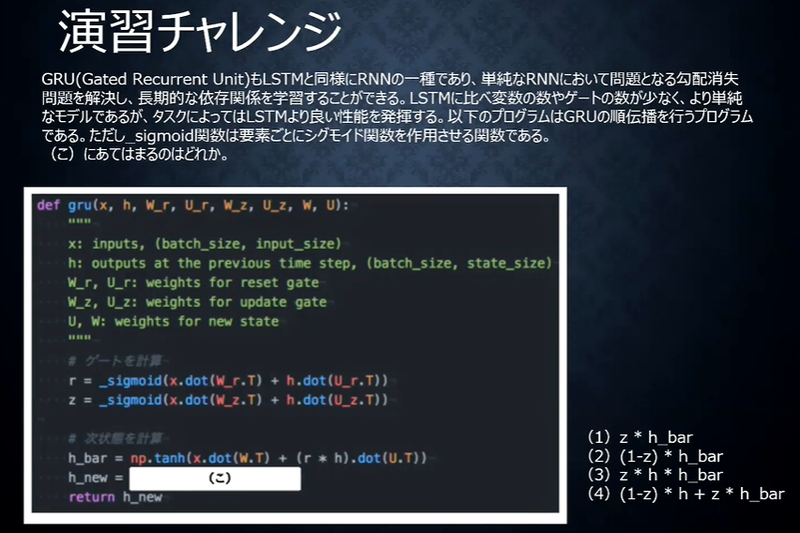
答え
(3)
確認テスト

答え
LSTMは
CEC、入力ゲート、出力ゲート、忘却ゲートから構成され、
多くのパラメータで時間をかけて学習する
GRUは
リセットゲート、更新ゲートを持ち、
LSTMよりもパラメータの少ない、シンプルなモデルとなっており、計算量が少なくなる。
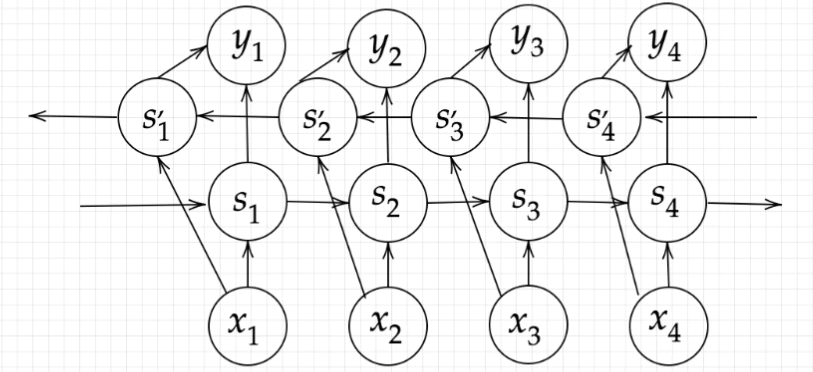
Section4:双方向RNN
RNNは過去の情報を保持することで時系列データの学習を実現してきた。 双方向RNNの場合は、過去の情報に加えて未来の情報も加味させるモデル。
例えば、文章中のある単語の次にくる単語は何かを予測させようとしたとき、 単語より前の情報だけでなく、後の情報も加味して学習すると精度は向上することが期待できる。
双方向RNNは、文章の推敲や機械翻訳等で実用されている。
演習チャレンジ
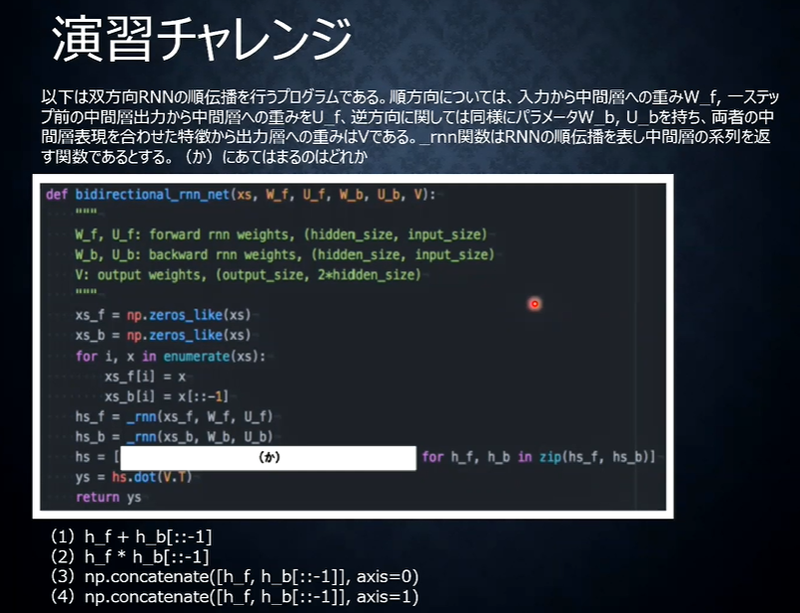
答え
(4)
axisは合体のさせ方を指示
0の場合、横方向に並べる
1の場合、縦方向に並べる 時間的に同じなら同じ場所に